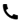自动语音识别(AutomaticSpeechRecognition简称"ASR")技术的目标是让计算机能够“听写”出不同人所说出的连续语音,也就是俗称的“语音听写机”,是实现“声音”到“文字”转换的技术。是一种使用计算机来识别人通过电话或麦克说话产生的语音信号的语音技术。作为专门的研究领域,ASR又是一门交叉学科,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。
人工智能技术的最新进展,推动呼叫中心向前一步。ASR(自动语音识别)转写普及,语音转文本实现自动化,大量录音数据都能快速完成转写,为客户价值的挖掘分析奠定基础。对于这项新技术的应用,有的企业选择为呼叫中心自建ASR转写工具,有的企业则选择引入专业的ASR转写服务。
在ASR中用到的最主要的技术是隐马尔可夫模型(Hidden Markov Model,HMM)。这种技术通过判断每个相邻小区的语音信号最可能是哪一个音素来识别单词,因为词汇表里的单词其实就是音素的组合。通过一种叫作Viterbi(一种动态规划算法,一般用于序列的译码)的搜索过程来决定最有可能是哪一个因素序列。搜索局限于词汇表的单词所对应的音素序列。ASR引擎的工作过程如图:

①前端语音处理:完成端点(话音的起始点和结束点)检测、降噪等。
②识别:根据声学模型、语言模型、语法进行识别。声学模型是语音识别系统中最关键的部分,它的作用就是前面提到的确定音素序列。语言模型是指语言中的一些规则或语法结构,是表现字或词上下文之间的统计模型。语言模型可以预测在句子中某个位置最可能出现的单词。语法对所有可能识别的语言进行描述,简单地说,语法告诉识别器应该听什么。语法可以用有向图来描述,图中的节点可以是一个单词或一个句子,如果识别成功,识别的结果将是图的一条路径。
③产生识别结果:识别结果按照一定的文本结构返回。
自动语音识别分类:
(1)按系统的用户情况分:特定人和非特定人识别系统;
(2)按系统词汇量分:小词汇量、中词汇量和大词汇量系统;
(3)按语音的输入方式分:孤立词、连接词、连续语音系统等;
(4)按输入语音的发音方式分:朗读式、口语(自然发音)式;
(5)按输入语音的方言背景情况分:普通话、方言背景普通话、方言语音识别系统;
(6)按输入语音的情感状态分;中性语音、情感语音识别系统。语音识别技术适用于家用电器和电子设备,比如电视、计算机、汽车、音响、冷气等的声控遥控器,电话、手机或PDA上的声控人名拨号、数字录音机的声控语音检索标签、儿童玩具的声控等;也可用于个人、呼叫中心,以及电信级应用的信息查询与服务等领域。
语音识别系统的性能因素
识别词汇表的大小和语音的复杂性;语音信号的质量;单个说话人还是多说话人;硬件平台。
语音识别技术的应用包括语音拨号、IVR语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译。
语音识别技术所涉及的领域
信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。特别是在电话机器人中的IVR起作重要的作用。
更新:2019-04-12 07:21:01
·
人看过